Writing software documentation is hard. Maintaining it is even more challenging in both closed and open-source worlds.
You are probably familiar with the disdain that everyone has for writing, maintaining, and updating documentation, especially software engineers. But it is a necessary process that helps future teams, users and developers to use your project and contribute effectively. It might be a factor between life and death for a project or adoption game changer.
Product or software documentation can be in the form of a user manual. It can also be an API specification for developer use. In addition, it can contain runbooks, troubleshooting guides and tutorials. Finally, if versioned, it will also act as a record for the past decisions in the form of proposals. All those pieces can create a single source of truth that can save a lot of time and energy. And having readable, up-to-date, quality documentation is always a blessing.

To motivate lazy engineers like ourselves or others (especially in open source, where many are not paid to do so!) to focus on documentation, we have to make our process of adding or changing them as frictionless and automatic as possible. Eliminate even minor pain points to a minimum. Reduce the burden. This is why we created a CLI tool called mdox.
This blog post was co-written by Saswata (GSoC mentee) and his mentor Bartek during Summer 2021 CNCF mentorship on the Thanos project.
Documentation as a Code
One would say that treating documentation as code is an example of using the wrong tool for the job. “When you have a hammer, then everything looks like a nail”, they say. But what if the symbolic hammer can be indeed reused?
Developers (typically) don’t write code in Google Docs and there are reasons for that:
- Code lives in multiple, linked files. Your code usually depends on other files that have to be stable for the deterministic code change. Things can’t be fluid.
- We want others to review and clearly approve the exact state of the code before publishing somewhere else (e.g production).
- We make mistakes that sometimes have to be reverted. We have ideas we want to return to. We want to check who was the author of the change. That’s why versioning is important.
- We want to automate the manual tasks. We want our code to be formatted, checked, tested and built automatically.
That is why the development happens in git repositories (versioning, stability) guarded by review systems e.g GitHub, GitLab, Gerrit etc (review-approve cycle) and automated with CI/CD systems (automation).
Now guess what, we have exactly similar issues when changing software documentation:
- Documentation also lives in multiple, often linked files. You often want to link to other resources: images, code, blogs, website or other headers/sections of your documentation.
- We also want others to review and clearly approve the exact state of the documentation before publishing. There is nothing worse than dangling Google Docs which are kind of unfinished, kind of approved a long time ago, but changed dramatically since then. It’s worse if this piece of documentation is a decisive design proposal.
- Arguably documentation mistakes are often less critical than software ones. Yet being able to see what was changed in the past and by whom is invaluable. Especially if we want to ask the author for follow-ups! 😈 Versioning is still important.
- We are in 2021 and many documentation manual tasks can be automated. Formatting, checking for misspells or even grammar mistakes. Not to mention those poor links and code examples that need to be updated all the time. Last but not least, publishing on “green”. What if we can automate all of those too using CI/CD systems?
We would argue that our code “hammer” can be actually useful for documentation in more cases than not. In the end, documentation is a code for… humans! That’s why we recommend to:
- Version your documentation files in git.
- Use the Pull Request/Merge Request feature to review at least bigger documentation changes.
- Use CI (e.g Github Actions) to automate manual checks and tasks.
- Keep your documentation close to code, ideally in the same repository if possible for ease of use.
From that, you can either use a platform like GitHub or GitLab to render your documents for even non-dev readers or build a quick and (free!) website to render it under your (or free) domain. In this blog post, you will learn about a tool that helps achieve… both!
Markdown: This is the Way
You can totally write your documentation in simple, non-formatted txt files. Yet, in the end, documentation has to be clear and readable, so some styling is extremely useful. Think about basics like those nice, highlighted links, different headers marking sections, code examples, bolded or italic sentences.
To satisfy all readers, in the end, your documentation has to land as some HTML in somebody’s browser. This supports any kind of styling, but unless you are CSS mad nerd, you don’t want to write and ask others to write in raw HTML and CSS (:
There is, however, an amazing balance of basic features and simplicity of writing: Markdown language, and notably the Github flavour of it GFM explained below.

Most open-source projects maintain documentation using markdown. This markup language is preferred over anything else, and there are reasons for that:
- Dead simple syntax for writing nice and structured documents which are readable even when they are not rendered.
- There exists a well documented and maintained spec called GitHub Flavored Markdown. It clarifies certain ambiguities of past specs and extends markdown syntax by adding support for tables, block content nesting, etc. Following this spec ensures that documents are rendered nicely on GitHub!
- Many static site generators like Hugo and Docusaurus support markdown. They can make a themed website directly from markdown content, with some additional configuration in the form of frontmatter.
There are alternatives to markdown, such as AsciiDoc and Wikitext (the markup language used by Wikipedia). Both are great, but they might be better for different purposes (Bartek: for example, AsciiDoc is great for writing books! I used it when writing my book with O’Reilly, it’s amazing.). But when it comes to software documentation, markdown is simpler and more adopted. And such great adoption leads to the existence of a multitude of tools!
Nothing is all Bright
However, no matter if code is written in Markdown or not, maintaining correct code examples, formatting, links, frontmatter, and everything in between seems like a herculean task. There are quite a few bumps we found when working with markdown with bigger CNCF communities like Kubernetes, Prometheus and Thanos that makes contributing or adding docs more painful than it should be:
- Formatting markdown is nice to have as it allows easier editing for future writers. Linters for markdown that tell you what is wrong do exist, but fixing must be done manually which is a brittle and time-consuming process as humans do make mistakes. In the end, you don’t want expensive developer time to be spent on ensuring the correct amount of newlines or characters in a single line, do you?
- Checking links is another painful process. Link checkers are available but in most cases, they are slow, abuse other websites or are not smart enough to understand your documentation structure.
- Code blocks are easy to introduce into docs, but keeping them up-to-date is another problem entirely! embedmd alleviates a lot of this by allowing you to copy over content from a file into a code block. But what about command outputs like
--helpcommands or something else that needs to be demonstrated, but isn’t saved in a file? - Website generators exist, but there are some obstacles. Frontmatter can be really confusing, it needs to be manually crafted for each markdown file. To change one, the writer has to be familiar with the whole project website setup (imagine contributing to such!). Also, in some cases, blank files with just frontmatter need to be added in order to maintain some condition(e.g website sidebar ordering). All those things do not render well on native platforms like GitHub, making it even more confusing and distracting. Furthermore, there is lot’s of magic with links that has to happen. (Things you don’t want to know: Link localization for multi-version docs, relative links change while shifting markdown content from one dir to another, which is a common use-case when dealing with website generators). Ideally, you want all of this to be fully transparent to the documentation contributor or maintainer!
Finally, how many tools are needed to tackle all these problems? Managing configuration for all of them requires having complex shell scripts/Makefile for some unified experience. Additionally, each tool has its own latency and performance issues, leading to huge “bake” times for documentation automation.
mdox: All in one solution and more!
Fortunately, there is now a way to tackle all these problems (and more) automatically using mdox! Great tooling should get out of your way and let you do exactly what you need to without causing pain, which is what we want to achieve with mdox.
mdox is a simple Go CLI tool, you can install using go get or pin using bingo.
Auto-formatting
Formatted markdown allows writers to understand documentation quickly and avoids surprises. On the other hand, it’s important to not expect writers to write perfect, formatted markdowns in a way you want. Even if you check certain formatting on CI, writers will get quickly annoyed when thrown into the loop of pushing changes, waiting for CI linter, see an error (output may just be the first error or simply incomprehensible), push again, learn about a new error elsewhere and repeat.. and lose a few hours in the process.
mdox solves those issues by formatting markdown files automatically, following the GitHub Flavored Markdown spec, and fails if it cannot format them. Simply, run mdox fmt <files>! If you want to run in CI, use mdox fmt --check <files>, which does not modify anything, just checks the output produced by mdox would be different than what was committed. If not, it will fail and specify exact diffs of what is not formatted or wrong.

fmt command ensures a smooth automatic experience for the contributor that also does not compromise the markdown quality of the project. Win-win situation!
Kudos to some Go developers who passionately started Kunde21/markdownfmt fork, our tool used internally for formatting, with goldmark parser help You might be surprised, but parsing and formatting markdown is quite advanced engineering in itself! We now maintain it, together with https://github.com/karelbilek, https://github.com/Kunde21 - a great open-source example!
Link Checking
Broken links are super annoying, especially in software documentation. Trying to figure out the correct link as you’re trying to learn something else is a distracting context switch. We can mitigate this by using a markdown link checker. However, most currently available link checkers seem to be underperforming, in a few ways:
- They just keep on visiting links. This results in obvious rate-limiting (“Too many requests” errors) especially from very often linked resources like GitHub (Just imagine CHANGELOG (: ). You can fully disable checking such links, but then might have surprises later on! You can enable retries or dev APIs in those cases, but still, it would either take a huge time or will be hard to set up.
- Some skip over relative links in markdown so those would still stay broken.
- Some cannot be run locally at all so a contributor cannot check before pushing and has to wait for CI.
This is why in practice, projects either disable link checking or add them as soft checks only (“never-fail” check, which means CI always passes, even if the link is failing).
mdox tries to solve link checking challenges in various, configurable ways:
- Relative links are checked.
- Links are gathered in a parsing and formatting routine.
- Links are checked concurrently.
- All links are “single-flighted” (the same links are checked once) and cached (can be even cached persistently using SQLite), meaning we do as minimal amount of slow and expensive link checking as needed.
- mdox has rich retry validation techniques that understand various response headers from websites e.g “Retry-After” HTTP header. It retries immediately for other status codes like 301, 307, and 503 as well.
- You can skip certain domains/paths if you want.
- You can enable debug metrics and profiling that shows the slowest links that contribute to link checking performance. Observability!
- Last but not least, mdox implements semantic link checking (also called “smart link validation”). Currently we support one, for common GitHub Issues and Pull requests links called
githubPullsIssues. You can read more about it below.
Practically, you can configure for each domain/path/regex a few type of validators:
ignore: This type of validator makes sure that mdox does not check links with the provided regex. This is the most common use case.githubPullsIssues: This is a validator which only accepts a specific type of regex of the form(^http[s]?:\/\/)(www\.)?(github\.com\/){ORG}\/{REPO}(\/pull\/|\/issues\/). It validates GitHub PR and issues links by fetching the GitHub API to get the latest pull/issue number and constructs matching regexes. This makes sure thatmdoxdoesn’t get rate-limited by GitHub, even when checking a large number of GitHub links but at the same time ensures that links are actually validated!roundtrip: All links are checked with the roundtrip validator by default(no need for including into config explicitly) which means that each link is visited and fails if the HTTP status code is not 200(even after retries).
This is what is currently implemented, but code is pluginnable to add more semantic link checking or other options. Contributions are welcome!
Auto Generation Code Documentation

Code blocks are pretty much a staple in software documentation. You need them to demonstrate any sort of configuration, and/or outputs or maybe even explain code. But it is also extremely painful to update these code blocks without any automation! There are other solutions like embedmd, but they are imperfect too:
- Need to have an explicit file with content that is needed for code block. While this is fine for something like a YAML code block, this creates problems when you want to demonstrate something like command line output in a code block.
- Relative links for files to embed. Each embedmd block will need a relative path to the file. Thus moving files around will lead to all of them breaking and would need to be manually fixed.
- Again, a completely separate tool for fixing and automating just one aspect of many problems.
mdox tackles this by allowing extra “code block” directives. You probably used them before to specify the language of the code you put in the code block. Guess what, markdown allows extra information to be passed too!
```go <extra block directives>
...
It’s as easy as adding mdox-exec=<command that produces output, which will be pasted to code block> to code block directives! You can pass user-defined shell commands whose output is then pasted into the code block by mdox. This has much more flexibility and composability than just copying from files and doesn’t require you to learn about additional configuration as it uses familiar Linux commands. Also, all commands specified are executed in the working dir, i.e, where mdox is running.
So want to copy a whole file into a code block? Use cat:
```go mdox-exec="cat main.go"
...
Want to copy a few lines instead? Use sed!
```go mdox-exec="sed -n '3,6p' main.go"
...
Want a custom CLI output, such as a --help command? Sure!
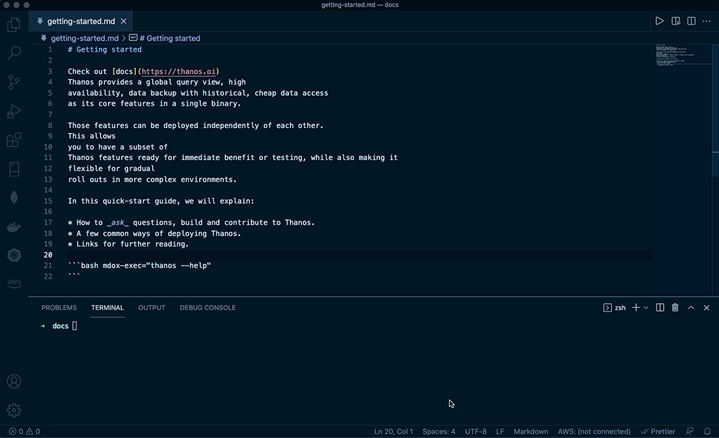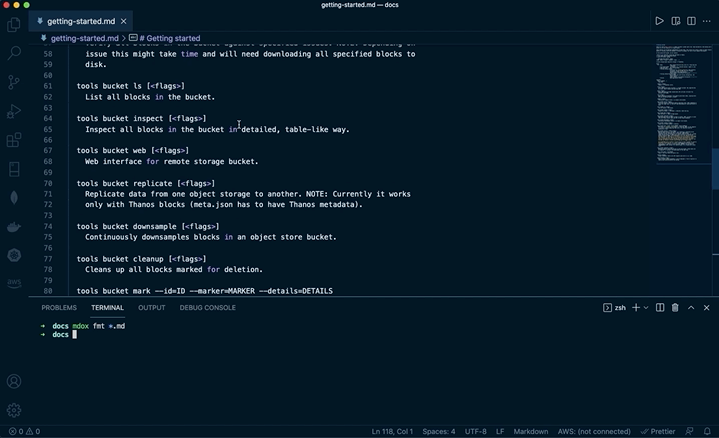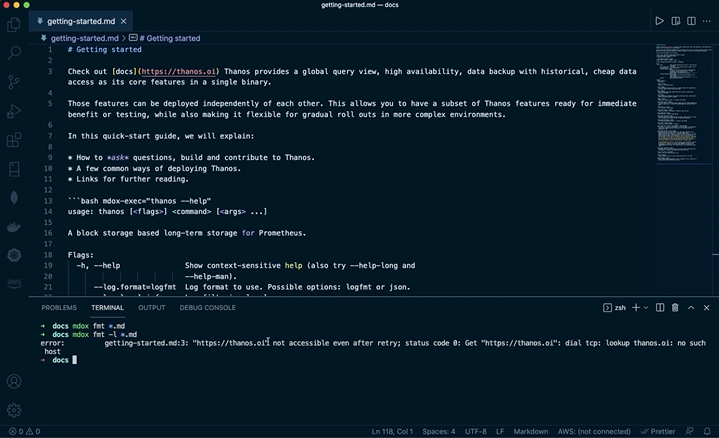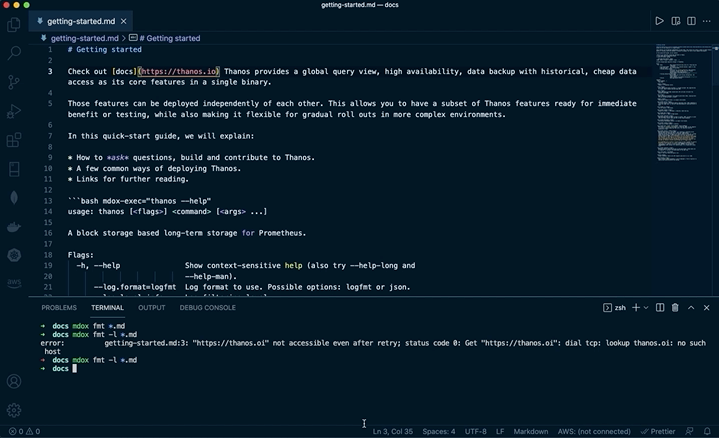
```bash mdox-exec="thanos --help"
...
Have a command which executes but with non-zero exit code? Use the mdox-expect-exit-code flag to specify!
```bash mdox-exec="go --help" mdox-expect-exit-code=2
...
It is much easier to maintain and it executes simultaneously as formatting, so no additional CI check is needed. All in one binary!
Production Use
We are already using mdox in a number of open-source projects! Notable CNCF and CNCF-adjacent projects such as Thanos, Observatorium, Red Hat Observability Group Handbook, Bingo, efficientgo/tools, and efficientgo/e2e are using mdox to check formatting and links on each PR.
Summary & Future
Thanks for reading this through! I hope you found this insightful. Feel free to try mdox out.
Any feedback and contributions are welcome! Just use GitHub Issues and Pull Requests as usual. 🤗 You can already look through open GitHub Issues and check those with help wanted labels.
Also, keep an eye out for Part 2 of this blog, which will explain how to use mdox transform and set up a sweet, static documentation website without hassle. In that part, we will explain how you can produce your docs in markdown without any website metadata boilerplate and still allow rendering and using them seamlessly in BOTH websites and GitHub! All without any scripts or frontend skills!
There are also further plans to improve mdox like adding new features such as persistent link caching and the option to generate YAML config directly from Go struct! Stay tuned, and give us feedback.
See you around!
Comments